
In October of 2017, Lee Fox introduced Austin DevOps to the concept of Software Archeology. The entire idea and analogy really struck at the heart of what I do.
Archeologists use specialized tools to unearth the behavior of complex social systems. The use of these tools must be painstaking in detail so as to have a minimal impact on the facts available about a society.
In software even the simplest of systems can be complex when no context exists. Consider a Django web application that has been in service for 5 years. Nobody remains from the team that set up they system. There was never an operations person.
Translated into the terms of archaelogy, we could say that there was no written language about how the system worked. There was nothing written about the culture of testing or security. There are no benchmarks for performance.
For years, my first move has been to look at basic systems monitoring. Things like disk usage, load average, network transfers and build patterns of behavior. However, in the last year, I have started in a different place: application logs.
Log Aggregation Provides Awareness
Even in a system with only three web servers and a database server, tracking down an issue to understand system behavior is a mind-numbing task. Opening multiple terminals, tailing logs, losing your place. In the extreme I have seen developers with 25 windows open watching for information to flow as they exercise a feature in hopes of a clue to what is wrong.
Not only is this inefficient, the friction to get this sort of information has two crippling consequences.
Troubleshooting is often not done and strange work arounds in the application code are frequent. (increased complexity)
Developers do not think about log exhaust as a first class output because it is not useful. This means logging by the application is … well … useless. (downward spiral)
Digging for History
I am not brought onsite at a customer because they have awesome situational awareness. My customers are the common 90%. They have a small application that they have built over time to run their business. The people who know how it work have left the organization. The customer wants to:
- add a feature
- scale the business
- track down stability issues
Yes there are other solutions with more power and more features. That is not what I need. I need answers to why the software behaves the way it does for a given stimulus. Papertrail’s time-to-value is its key feature.
After several hours using common cultural practices we found evidence of a Redis server that was not known to the current team.
Other tools like find were employed with common naming patterns like the .log extension.
Knowing the application came from the Django tribe of the Python nation we tracked down the settings.py files in each web root.
The result below is the 17 log files we had to track individually now codified in a simple file found at /etc/log_files.yaml.
files:
# cms logging
- path: /srv/www/example.com/logs/access.log
tag: cms/nginx/access
- path: /srv/www/example.com/logs/error.log
tag: cms/nginx/error
- path: /var/log/uwsgi/app/example.com.new.log
tag: cms/uwsgi
# spiffyawards logging
- path: /srv/www/spiffyawards.example.com/logs/access.log
tag: portal/nginx/access
- path: /srv/www/spiffyawards.example.com/logs/error.log
tag: portal/nginx/error
- path: /var/log/uwsgi/app/spiffyawards.example.com.log
tag: spiffyawards/nginx/error
# backoffice logging
- path: /srv/www/backoffice.example.com/logs/access.log
tag: backoffice/nginx/access
- path: /srv/www/backoffice.example.com/logs/error.log
tag: backoffice/nginx/error
- path: /var/log/uwsgi/app/backoffice.example.com.new.log
tag: backoffice/uwsgi
# portal logging
- path: /srv/www/portal.example.com/logs/access.log
tag: portal/nginx/access
- path: /srv/www/portal.example.com/logs/error.log
tag: portal/nginx/error
- path: /var/log/uwsgi/app/portal.example.com.new.log
tag: portal/uwsgi
# system wide application logging
- path: /var/log/nginx/access.log
tag: systemwide/nginx/access
- path: /var/log/nginx/error.log
tag: systemwide/nginx/error
- path: /var/log/uwsgi/emperor.log
tag: systemwide/uwsgi/emperor
- path: /var/log/example-example/django_log.log
tag: systemwide/django
- path: /var/log/redis/redis-server.log
tag: systemwide/redis
destination:
host: logs2.papertrailapp.com
port: 12345
protocol: udp
Some things of note for you about the organization of the file.
Papertrail does not require the tag but we have found, over time, that a strategy of system/component/log to be immensely helpful.
For example if there is an API called kfc that would be a system. Components of that system might be nginx and uwsgi in the Python world or Apache and php-fpm in the PHP world. Each will create their own log exhaust that has value to a person attempting to discover what the system is doing under stimulus.
Paydirt
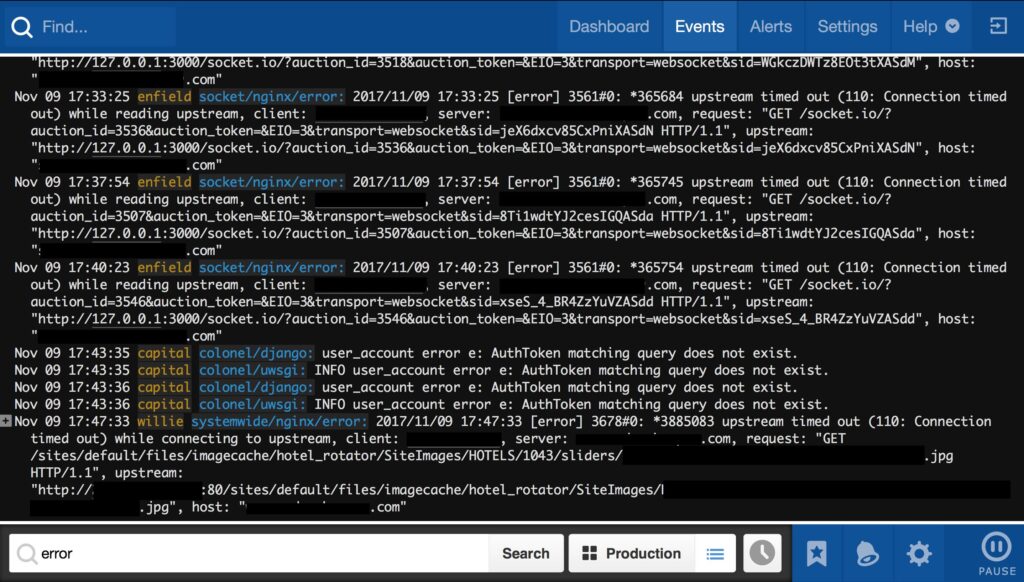
The screen above is a search across 5 snowflake servers and more than 100 log files. You can see that it is only showing log messages with the word “error” in them. If I need to look for errors only from the subsystem “colonel” then I can simply change the search parameters to “error AND colonel”
Ultimately the above represents a “single pane of glass” for everything the system can tell me about what it is doing.
Learning from the Past
Of course, on this customer site, we learned a great deal about what was going on and used this to help us improve their system stability and reconstruct the knowledge necessary to keep the business profitable.
But you, as a developer, can also learn from the past.
It should be apparent from the above Papertrail screen capture that there are far too many errors happening. This is the culture of “works-on-my-laptop”.
Consider that Papertrail will push alerts to chat and alert services. To reinforce that capability note the screen shot below and note that it is bereft of any value.
Because the signal to noise ratio of the logs is so low (i.e. there are so many meaningless errors in a given time period), we cannot yet use the tool to alert us if there is a problem.
This is a typical problem in operations. Developers do not produce effective log messages and product owners do not enforce any sort of standard.
Considering the case above, there are two behaviors that must change to move from the “works on my laptop” culture to the DevOps culture of “makes-us-money”.
Investigate Each Error
For every error in the log, a ticket should be opened and the error should be investigated.
Many log messages emitted as errors are, in fact, expected behavior. If an error expected, then it is not an error in the context of application logging. It should be set to the INFO level. They are still being logged, but they are only informational in nature.
In less frequent cases the error is, in fact, an error. In this case it should be addressed.
The goal is an ERROR and CRITICAL free log. With that as the goal, when most of the noise is removed, then alerting can be created to wake people up at night when CRITICAL events occur and to force a morning reaction when ERRORs happen.
In this way, the logs have operational value beyond the forensic. They become a key part of monitoring the health and performance of the system.
Verbose Errors
The messages in the search box screen capture above are, at best, cryptic. Each takes its own “dig” to get the meaning from.
When you, as a developer, decide to log any message, it should, in the minimum, include the file and line number when the error occurred. Additional context in the form of a message with key parameters will save time.
In a production incident, effective log messages reduce the time to resolution (TTR) and the general stress level of the team.
The Logging Tool
On a software dig, the logging tool is the primary window into the behavior of the system. If your system monitoring is going nuts, the logs are the most likely place for you to find out why.
Get log aggregation in place and use it to improve your teams knowledge of your system over time.
If you are in the process of building a system, use log aggregation to drive the creation and enforcement of useful logging standards that assist the first responders when things go wrong.
Archeological dig, brown field or green field … log aggregation will save you time and improve your production system.

